

Social Marketing
The term social marketing refers to influencing a target group in such a way that it accepts, rejects, or changes a behavior. ... Continue readingSocial Marketing

noindex is an attribute that is used in the HTML code of a website. Through this entry in the metadata, you tell the Googlebot when crawling your website that it should not include it in the index. This means that this page cannot be found in the SERPs of Google. You can thus directly influence which pages of your website should be found and which not.
Webmasters like to use this function for example for the development phase of websites and remove the tag as soon as the page goes online. Noindex is also used when content is similar or duplicates occur. This avoids duplicate content.
By including the “noindex” command in your HTML code, you can prevent unwanted pages from appearing in search results. For the implementation you have two options:
When crawling the website, Google reads the source code of the page. By using a so-called X-Robots tag, you can instruct the robot not to index this page.
Example for a X-Robots-Tag:
| HTTP/1. 1 200 OK (…) X-Robots-Tag: noindex (…) |
For this variant of implementation to work, the meta tag must be in the head section of the HTML document.
Example for a Meta-Tag:
| <meta name= ‘‘robots“ content= ‘‘noindex“> |
However, in many CMS systems, such as WordPress, there are already corresponding functions in the backend that enable the implementation of the tag by mouse click. Programming knowledge is no longer mandatory for the user here.
The “noindex” command can be additionally supplemented by the two attributes “nofollow” and “follow”.
The “nofollow” attribute additionally gives Google the signal that the corresponding links on the website should not be crawled or linked to the linking web pages.
The “follow” feature has exactly the opposite effect. Although Google does not want the page to be displayed in the SERPs, this attribute tells the Googlebot that it should still follow the links on the page. However, we would like to advise you not to use this variant, because you do not give Google a clear indication of how it should treat the page and the links on it.
John Mueller wrote about this on the WordPress Twitter blog:
„I’d assume most people & search engines will take you by your word. “fine” = ok, “noindex” = don’t bother with this page. Sometimes more can happen (“are you really fine?”, “what about this link?”), but the default is what you specify.“
It makes sense to set individual pages of your website to “noindex” from the outset. This includes for example:
These pages contain information that is important for the user of your website, but is not specifically searched for on Google. So that these pages do not land in the ranking before the important content of your website, you can set these with a clear conscience on “noindex”. You can also exclude pages with similar or duplicate content here.
Every website is crawled by Googlebot at regular intervals. Google checks whether there is new content on the page or whether the website still exists. If you subsequently set a page to “noindex”, it will only be removed from the index with a time delay. However, it is not possible to name an exact time window in which the adjustments are taken over. On average, according to Google, the pages are visited and crawled again after 6 months at the latest. However, this factor is highly variable, because the visit frequency for URLs by the Googlebot is related to an algorithm specially designed by Google. Depending on the importance of the URL, the change may already have been accepted after 14 days.
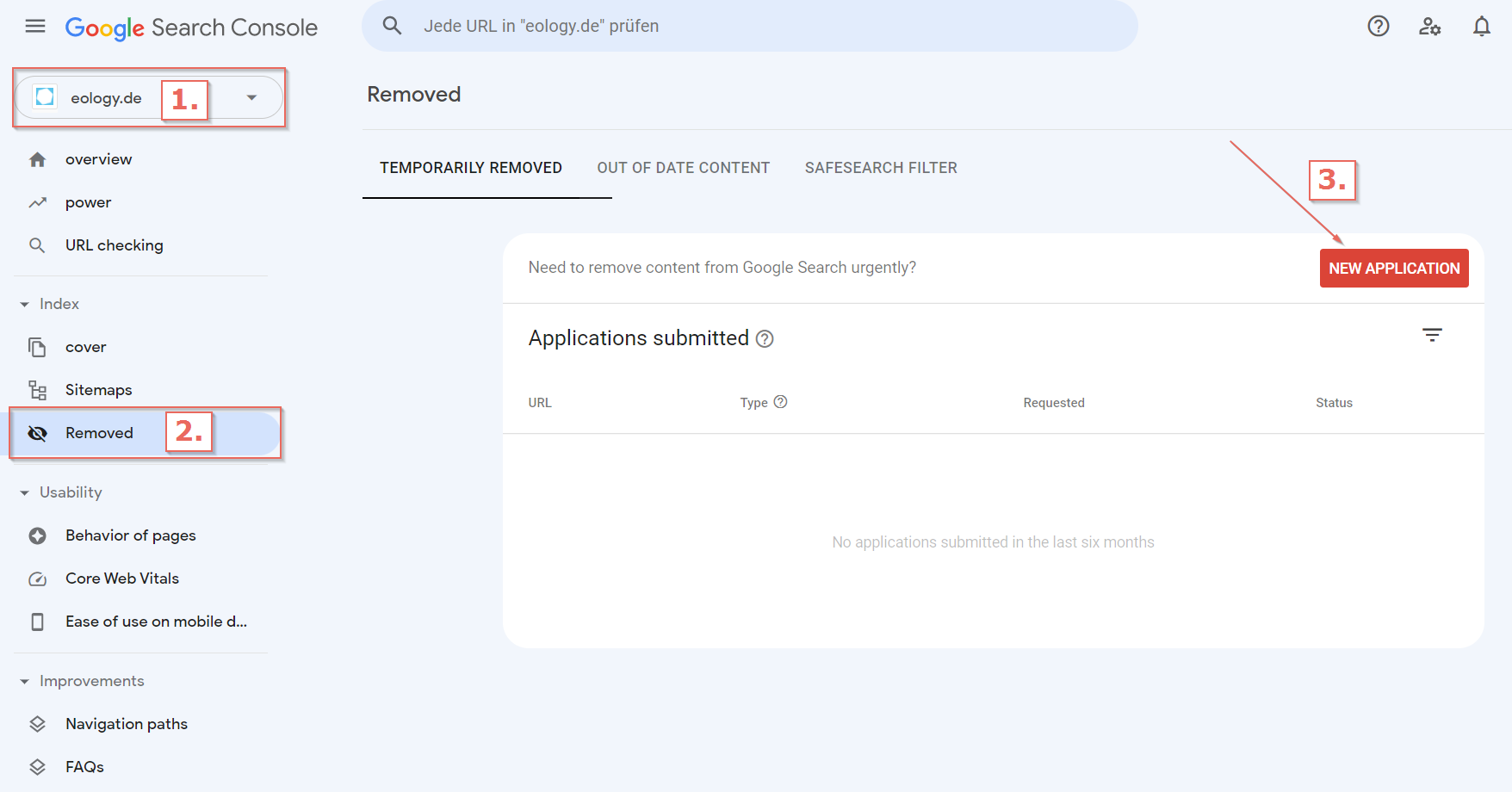
If you ever want to have a URL deleted from the Google SERPs, you can submit a request for this. For this you need a current access to the Google Search Console. Once you are logged in, you have the option to select your “Property”. Then select the item “Remove”. Here you will get to the area where you can submit your request to Google. Your specified page will now appear among the submitted requests and is temporarily removed from the search results. Once your request has been reviewed, the view will move to the “Outdated Content” tab in the best case. Do not make these URL removal submissions to Google lightly, as this is final.
The term social marketing refers to influencing a target group in such a way that it accepts, rejects, or changes a behavior. ... Continue readingSocial Marketing
With "Google Advanced Search" you can narrow down your search results on Google and thus search more specifically for keywords. In addition, you limit the results of complex search queries. Click here to get more information! ... Continue readingGoogle Advanced Search
Virtual influencers are digital avatars designed for use on social media. These characters interact there just like human influencers. Find out more in the article. ... Continue readingVirtual Influencer
You want to learn more about exciting topics?